Knowledge graphs turn scattered facts into connected data. Nodes stand for people, places, things, and ideas. Edges describe how they relate. Large language models can help at two moments that used to be slow: pulling structured facts out of messy text and translating plain questions into graph queries. Put together, you get a pipeline that reads content, adds clean triples, and answers questions with traceable paths.
Start by agreeing on words. A triple is subject–predicate–object. A schema names your node types and allowed links. A store is where the graph lives, such as a property graph or an RDF database. With those basics set, you can plan the build and the query path with steady, testable steps.
Pick a narrow domain first. Wide scopes create fuzzy edges and messy links. Write a one-paragraph purpose that sets boundaries and sample questions you expect to answer. From that, sketch a simple schema. List a handful of node types and the relations that matter. Keep names short and literal. “AUTHORED_BY” says more than “HAS_ASSOCIATION.” Add a few must-have properties for each node type, like a canonical name, one or two IDs, and timestamps. This early clarity keeps extraction focused and keeps later queries readable.
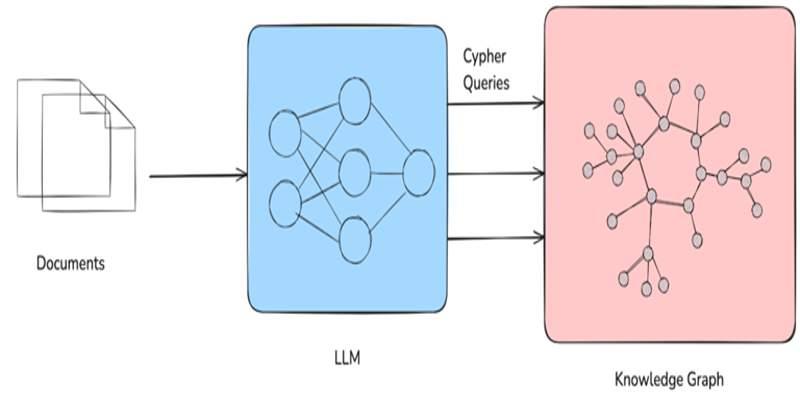
Gather a small, clean corpus to start. Convert PDFs, docs, and web pages to plain text. Strip boilerplate, ads, and navigation. Split long files into short, coherent chunks. Keep the chunking rule boring and regular, such as paragraph blocks or fixed character windows that respect sentence ends. Save the source path and a stable snippet ID with each chunk. You will need that later to cite where a triple came from.
Use the LLM to read each chunk and return candidate triples that match your schema. The prompt should be strict. Name the allowed node types and relations. Ask for a compact JSON array with fields for subject, predicate, object, and evidence span. Ask the model to skip anything that does not fit the schema. A tidy response beats a long, flowery one. Keep temperature low to reduce drift. If a chunk has nothing useful, the right output is an empty list.
Now filter. Reject triples that use relations you did not list. Drop ones missing a subject or object. If the evidence span does not actually contain the claim, discard it. These simple rules catch many early mistakes without heavy code.
Two strings may refer to the same thing. Build a light resolver that maps raw names to canonical nodes. Start with exact matches on a case-folded label. Add known IDs when you have them, such as catalog numbers or stable URLs. Then use the LLM sparingly to judge near matches when simple rules are not enough.
Give it two candidate records and ask if they represent the same entity under your domain rules. Log every decision with the reason and the confidence so you can audit later. When in doubt, keep them separate and mark them for review. Bad merges are harder to unwind than missed links.
Pick a graph store that supports your style: property graph with Cypher-like syntax or RDF with SPARQL. Create indexes on labels and key properties. Load nodes first, then load edges. Attach provenance to each triple: source document ID, snippet ID, and a creation timestamp. This makes answers traceable and lets you replay or roll back when you improve extraction.
Shape rules catch problems early. Require that an “AUTHORED_BY” edge links a Work to a Person. Require that a “PUBLISHED_ON” edge carries a date. Run a nightly pass that checks these rules across the graph and reports violations. Fix them at the source when possible by adjusting prompts, filters, or the schema. A short feedback loop raises quality faster than a giant clean-up sprint later.
There are two ways to query. Power users can write Cypher or SPARQL by hand. Most people will not. Here, the LLM acts as an interpreter. Give it a brief schema card that lists node types, relations, and a few property names. Ask it to translate a plain question into a safe, parameterized graph query. Then execute that query, collect the results, and compose a short answer that cites the nodes and edges used.
Keep the interpreter honest. If the question cannot be mapped to allowed relations, return a polite failure that says what is missing. If the query returns nothing, say so and avoid guessing. Small guardrails make answers predictable and help users trust the system.
Graphs are great for “who, what, where, when.” Sometimes you need a sentence for nuance. After you run the graph query, fetch the evidence snippets tied to the nodes or edges you returned. Use the LLM to assemble a tight answer that pulls facts from the graph and quotes short lines from the source text. This hybrid approach keeps replies grounded and readable.
Track precision and recall on a labeled sample. You do not need a huge set. A few hundred examples scored by a human go a long way. Count how often the extractor emits a correct triple, how often it misses an obvious one, and how often it strays. Review the worst offenders each week. Many errors repeat: wrong relation, swapped subject and object, or claims with no evidence span. Fix the root cause in prompts and filters, not only in post-processing.
For the question router, record the input, the generated query, the parameters, and the final answer. Add a confidence score based on simple signals: did the query compile, how many rows came back, how many edges were involved, and were citations found. Sample a set daily and review it. Tighten the schema card and add tiny examples only where the model trips. Short cards teach better than long essays.
Data shifts. New documents arrive. Names change. Keep your pipeline versioned. Tag each batch with a run ID and tie it to the code and prompt versions used. If a batch harms quality, roll back by run ID and reprocess after a fix. This discipline saves time when a supplier changes a file format or a scraper starts returning odd text.
Cache extraction outputs by chunk hash so you do not pay twice for identical text. Batch small chunks to cut overhead. Time each stage and keep a simple dashboard: chunks per minute, triples per chunk, rejection rate, average query latency, and error counts. When numbers drift, you will see it early. Slow, quiet failures leave the graph stale and answers stale with it.
Do not overspecify the schema on day one. Rigid models force hacks. Start lean and expand as questions grow. Do not accept relations that sound clever but carry no testable meaning. Plain verbs beat fancy labels. Do not hide provenance. If you cannot show where a claim came from, it will be hard to trust the result. And do not skip a human loop. A short, regular review beats a quarterly fire drill.
A small, well-scoped knowledge graph paired with a careful LLM pipeline can turn scattered text into connected facts and answerable questions. Keep the schema tight, the prompts strict, the filters simple, and the logs clear. With steady habits, your graph grows cleaner, your questions run faster, and your answers carry citations that make sense.

Failures often occur without visible warning. Confidence can mask instability.

We’ve learned that speed is not judgment. Explore the technical and philosophical reasons why human discernment remains the irreplaceable final layer in any critical decision-making pipeline.

Understand AI vs Human Intelligence with clear examples, strengths, and how human reasoning still plays a central role

Writing proficiency is accelerated by personalized, instant feedback. This article details how advanced computational systems act as a tireless writing mentor.

Mastercard fights back fraud with artificial intelligence, using real-time AI fraud detection to secure global transactions

AI code hallucinations can lead to hidden security risks in development workflows and software deployments

Small language models are gaining ground as researchers prioritize performance, speed, and efficient AI models

How generative AI is transforming the music industry, offering groundbreaking tools and opportunities for artists, producers, and fans alike.

Exploring the rise of advanced robotics and intelligent automation, showcasing how dexterous machines are transforming industries and shaping the future.

What a smart home is, how it works, and how home automation simplifies daily living with connected technology

Bridge the gap between engineers and analysts using shared language, strong data contracts, and simple weekly routines.

Optimize your organization's success by effectively implementing AI with proper planning, data accuracy, and clear objectives.